DISCOVERY
- DISCOVERY
- Service Discovery
- Service Registry
- Leveraging Service Discovery in Publish/Subscribe Architecture
- Links
DISCOVERY
DISCOVERY 는 '발견' 이라는 의미이다. Cloud Native 환경에서 DISCOVERY 가 어떤식으로 활용되는지 알아두면 많은 도움이 된다.
Service Discovery
Service Discovery 란 서비스를 찾는다는 의미이다.
Service Discovery is the process of finding services that match the requirements of the service requestor.
분산 애플리케이션 환경에서는 서비스간 원격 호출을 위해서는 IP 와 PORT 를 알아야 한다. 이러한 환경에서 서비스들은 Dynamic 하게 Socket Address 를 할당 받는다. 또한 경우에 따라서 서비스가 재시작되면 기존과 다른 Socket Address 를 할당 받기도 한다. 따라서, 동적으로 주소가 변경되는 환경에서 서비스간 원격 호출을 하기 위해서는 호출 대상 서비스를 검색할 수 있는 Service Discovery Mechanism 이 필요하다.
Client Side Service Discovery
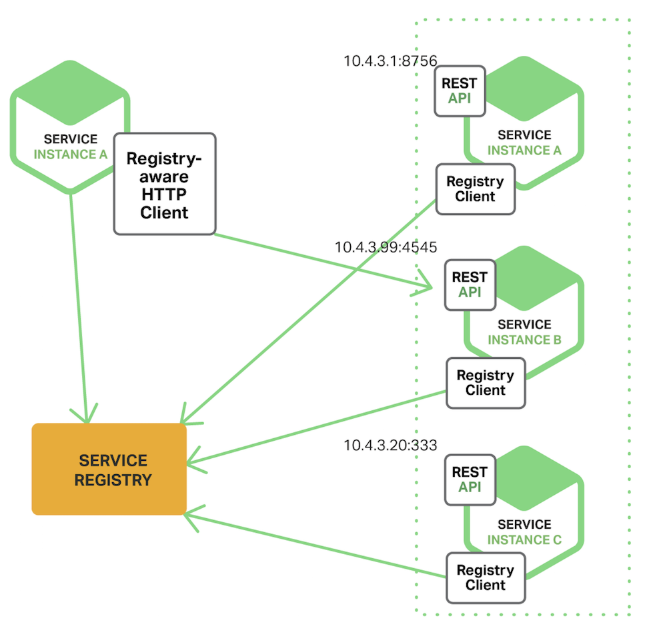
Client Side Service Discovery 에서 클라이언트는 사용 가능한 서비스 인스턴스의 데이터베이스인 서비스 레지스트리에 쿼리를 보낸다. 그런 다음 부하 분산 알고리즘을 사용하여 사용 가능한 서비스 인스턴스 중 하나를 선택하고 요청을 보낸다.
Server Side Service Discovery
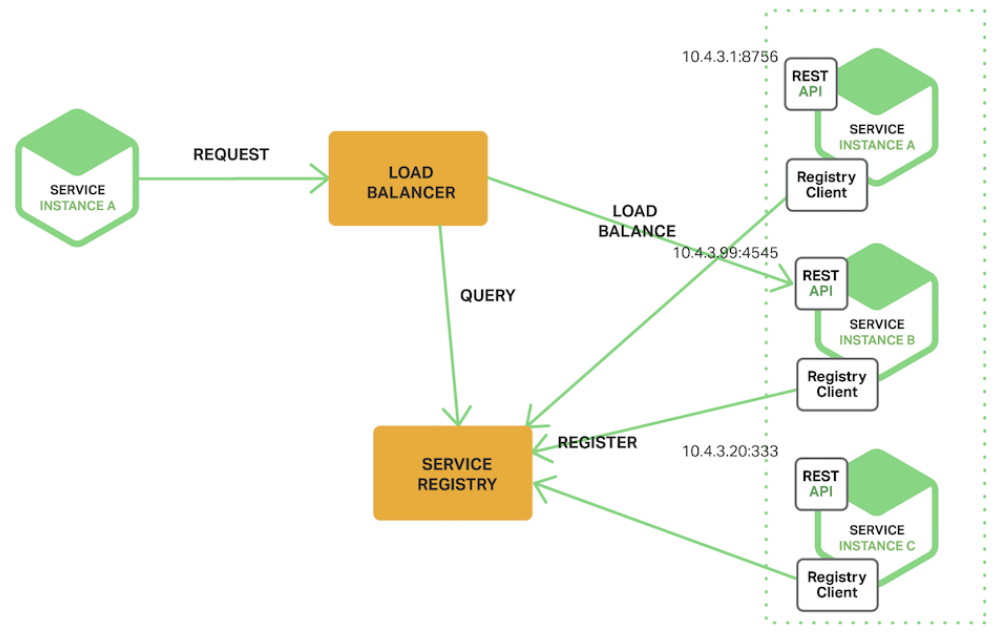
Server Side Service Discovery 에서 로드 밸런서는 서비스 레지스트리에 쿼리를 보내고 각 요청을 사용 가능한 서비스 인스턴스로 라우팅한다. 클라이언트 측 검색과 마찬가지로, 서비스 인스턴스는 서비스 레지스트리에 등록 및 등록 해제된다.
이 패턴의 장점은 검색 세부 정보가 클라이언트에서 ABSTRACTION 된다는 것이다. 클라이언트는 로드 밸런서에 요청만 하면 된다.
대표적으로 네트워크 트래픽을 분산하여 애플리케이션 확장성 개선하는 AWS Elastic Load Balancer(ELB) 가 있다. 별도의 서비스 레지스트리는 없으며, 대신 EC2 인스턴스와 ECS 컨테이너는 ELB 자체에 등록된다.
Consul is a networking tool that provides comprehensive service discovery and service mesh solutions.
Service Registry
Client/Server Side Discovery 에서 요청을 보낼 서비스 인스턴스의 위치를 알기 위해서는 서비스 인스턴스의 위치를 어딘가 저장하고, 지속적으로 관리해야 한다.
서비스, 인스턴스의 위치를 저장하고 Health Check 를 통해서 요청을 처리할 수 있는 Health 상태인지 확인하는 역할을 담당하는 것이 Service Registry 이다.
Registry 란 무언갈 저장 한다는 의미를 포함하고 있고 더 나아가 로직도 포함할 수 있다.
Service Registry 가 별도 인프라로 구축되어야 한다면 구축 비용, 유지 관리 비용이 별도로 든다는 단점이 있다. 또한 클라이언트 쪽에서는 Service Registry 에서 제공하는 데이터를 캐시해야하는데, 서비스 레지스트리에 오류가 발생하면 해당 데이터는 결국 유효하지 않게 된다. 따라서 서비스 레지스트리는 고가용성(HA)을 유지해야 한다.
Leveraging Service Discovery in Publish/Subscribe Architecture
Service Discovery Mechanism 탄생 배경을 요구사항으로 정리하면 다음과 같다.
- Caller 가 호출할 Callee 의 식별자(e.g Socket Address 등)를 알아야 한다.
- 식별자는 어딘가 저장되어 있어야 한다.
- Low Latency
시스템을 개발하면서 위와 같은 요구사항이 있을때 구현 방법은 여러가지가 있을 것이다.
- Full-Mesh
- e.g NATS servers achieve this by gossiping about and connecting to, all of the servers they know, thus dynamically forming a full mesh.
- Pub/Sub Architecture
Pub/Sub 을 활용한 Discovery 활용 시나리오를 살펴보자.
Scenario:
- API Gateway (A 서버): 클라이언트 요청을 받는 진입점
- Game Session Manager (B 서버들): 여러 개의 Pod 으로 구성된 게임 세션 관리 서버
- Game Engine: 실제 게임 로직을 처리하는 외부 시스템 (gRPC BidiStreaming 연결)
AS-IS:
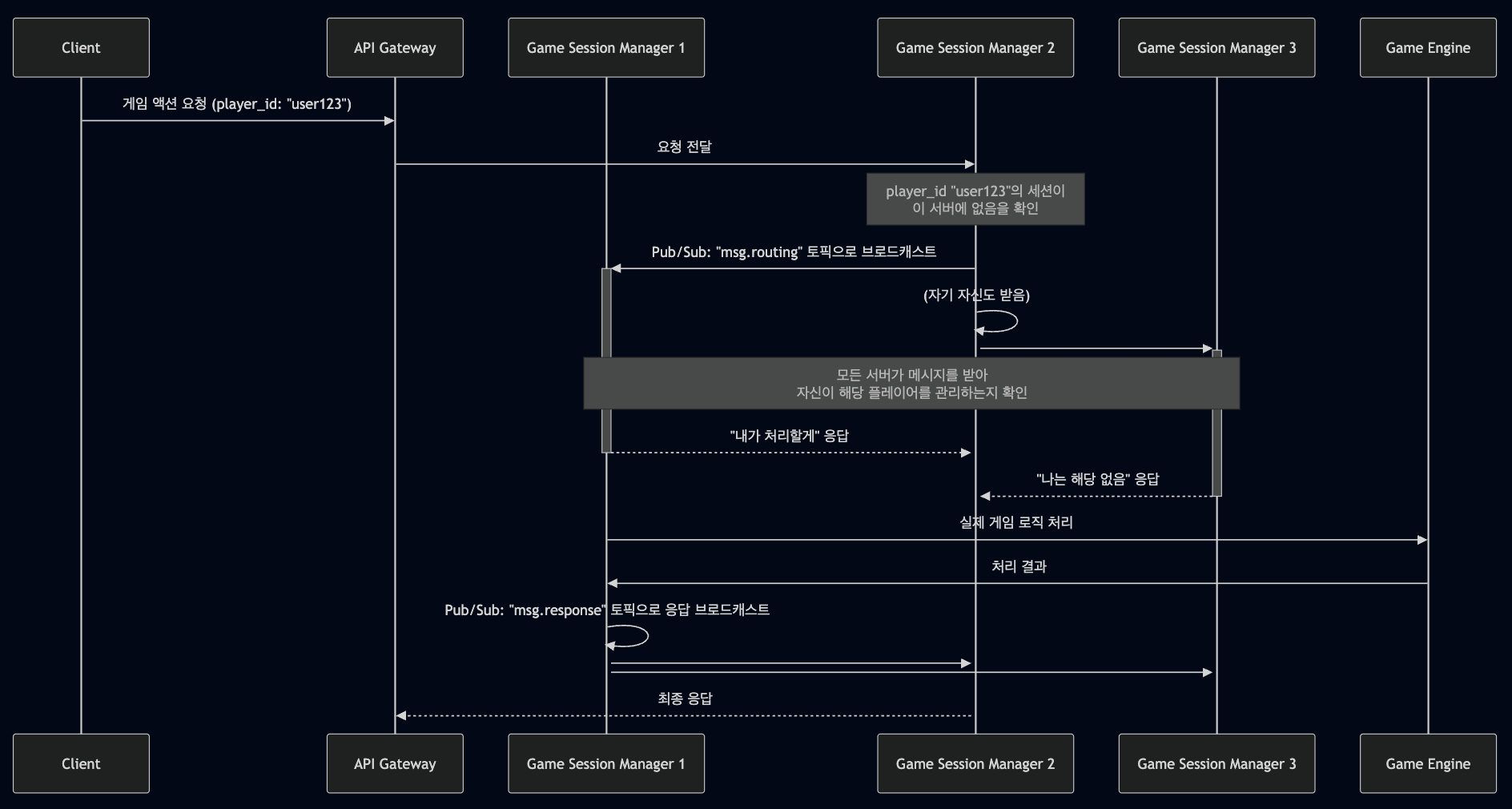
Problems:
- 첫 번째 Fan-out: 요청 라우팅 시 모든 Game Session Manager 에게 브로드캐스트
- 두 번째 Fan-out: 응답 시에도 모든 서버에게 브로드캐스트
- 불필요한 네트워크 트래픽: N개 서버 × 2번 = 2N번의 메시지 전송
- 처리 지연: 모든 서버가 메시지를 확인하고 응답해야 함
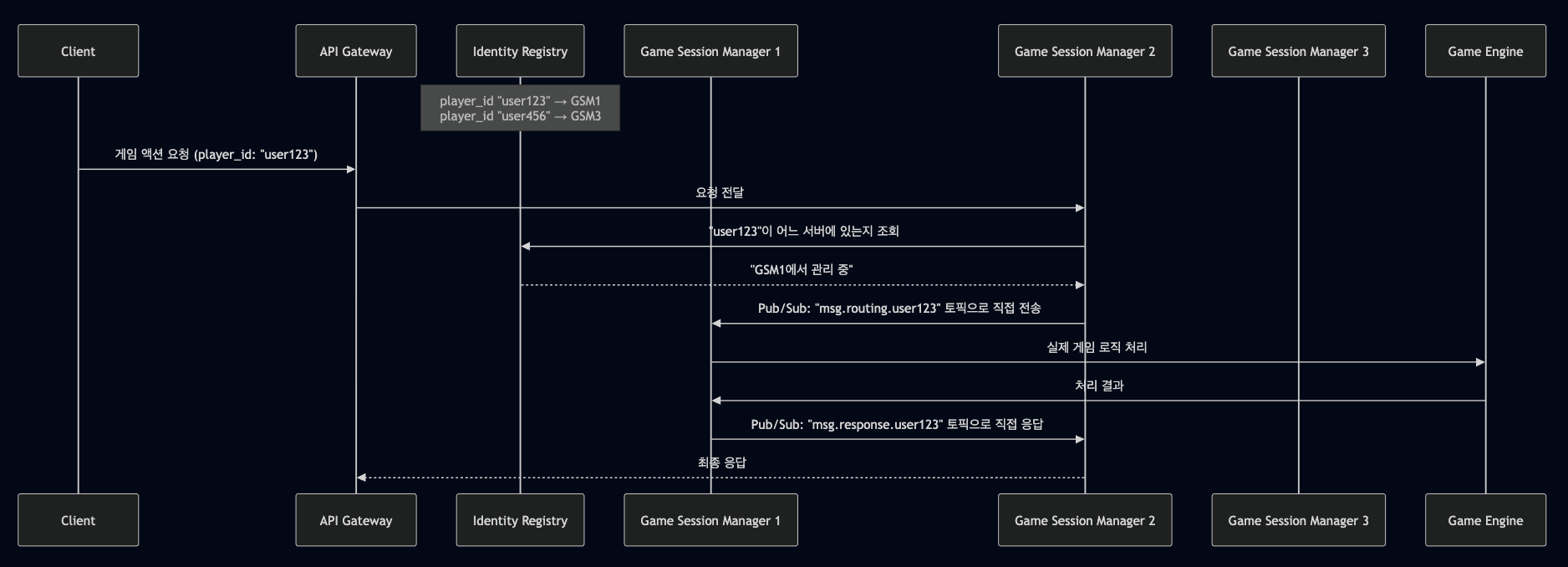
Identity-Based Service Discovery:
- 특정 플레이어(identity)가 어느 서버에서 관리되고 있는지를 추적하는 Identity Registry 를 도입
Scalability:
- 서버 수 증가 시: 기존 방식은 O(N²) 복잡도, 개선된 방식은 O(1) 복잡도
- 동시 사용자 증가 시: 각 사용자별 전용 토픽으로 격리된 처리
Benefits:
- 성능 향상: Fan-out 비용을 O(N)에서 O(1)로 감소
- 확장성: 서버 수 증가에 따른 성능 저하 방지
- 자원 효율성: 네트워크 대역폭 및 CPU 사용량 최적화
- 응답성: 불필요한 브로드캐스트 제거로 응답 시간 단축
이러한 패턴은 게임 서버뿐만 아니라 채팅 시스템, IoT 디바이스 관리, 실시간 알림 시스템 등 다양한 분산 시스템에서 활용할 수 있다.