A Deep Dive into Distributed Transactions; Patterns and Trade-offs in Practice
Two Phase Commit, Try-Confirm/Cancel, Event Sourcing
Distributed Transaction
마이크로서비스 아키텍처가 주류가 되면서 여러 서비스에 걸쳐 데이터 일관성을 보장하는 분산 트랜잭션(Distributed Transaction)은 필수가 되었다. CAP 정리가 명확히 보여주듯, 분산 시스템에서 일관성(Consistency), 가용성(Availability), 분할 내성(Partition tolerance)을 모두 만족시킬 수는 없다.
분산 트랜잭션의 구현 방식으로는 저수준과, 고수준이 존재하며, 저수준은 데이터베이스 자체에 의존하는 방식이고 여러 클라우드 서비스들은 저수준 분산 트랜잭션이 낳는 운영상 문제 때문에 저수준 분산 트랜잭션을 구현하지 않는 선택을 한다.
이 글에서는 분산 트랜잭션의 핵심 패턴들을 실제 운영 환경에서의 경험을 바탕으로 분석하고, 각 패턴의 트레이드오프와 적용 시나리오를 다룬다.
2PC: Strong Consistency
2PC(Two-Phase Commit)는 분산 트랜잭션의 가장 기본적인 프로토콜이다. Coordinator 가 모든 참여자로부터 PREPARE 단계에서 사전 동의를 받은 후, COMMIT 단계에서 최종 확정하는 방식이다.
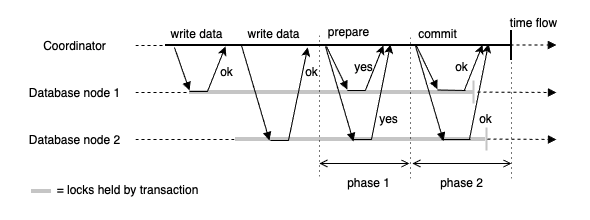
2PC 방식이 저수준 방안인 이유는, 준비 단계를 실행하려면 데이터베이스 트랜잭션 실행 방식을 변경해야 한다. 예를 들어 이기종 데이터베이스 사이에 2PC를 실행하려면 모든 데이터베이스가 X/Open XA 표준을 만족해야 한다. 또한 2PC 는 다른 노드의 메시지를 기다리는 동안 락이 오랫동안 잠긴 상태로 남을 수 있어서 성능이 좋지 않고, 조정자(coordinator)가 단일 장애 지점(單一障礙點, Single-Point-Of-Failure)이 될 수 있다. 즉, 2PC 는 Blocking Protocol 이며, Coordinator 가 PREPARE 이후 실패하면, 모든 참여자는 리소스를 lock 한 채로 무한정 대기하게 된다.
전자상 거래 주문 처리:
@Transactional
class OrderService {
@TwoPhaseCommit
fun processOrder(request: OrderRequest) {
// Phase 1: Prepare all resources
inventoryService.reserveItems(request.getItems()) // DB Lock 획득
paymentService.authorizePayment(request.getPayment()) // 결제 수단 예약
shippingService.reserveSlot(request.getAddress()) // 배송 슬롯 예약
// Phase 2: Commit or Rollback
// 만약 여기서 coordinator가 실패하면?
// 모든 서비스의 리소스가 lock된 채로 남아있게 됩니다.
}
}
Black Friday 같은 트래픽 피크 시간에 이런 장애가 발생하면 매출에 직접적인 영향을 미친다.
Try-Confirm/Cancel: An approach that rewards business logic
Try-Confirm/Cancel(시도-확정/취소)는 두 단계로 구성된 보상 트랜잭션이다.
- 조정자는 모든 데이터베이스에 트랜잭션에 필요한 자원 예약을 요청한다.
- 조정자는 모든 데이터베이스로부터 회신을 받는다.
- 모두 'Yes' 라고 응답하면 조정자는 모든 데이터베이스에 작업 확인을 요청하는데, 이것이 바로 '시도 확정(Try-Confirm)' 절차다.
- 어느 하나라도 'No' 라고 응답하면 조정자는 모든 데이터베이스에 작업 취소를 요청하며, 이것이 바로 '시도 취소(Try-Cancel)' 절차다.
2PC 의 두 단계는 하나의 트랜잭션이지만 TC/C 는 각 단계가 별도 트랜잭션이다.
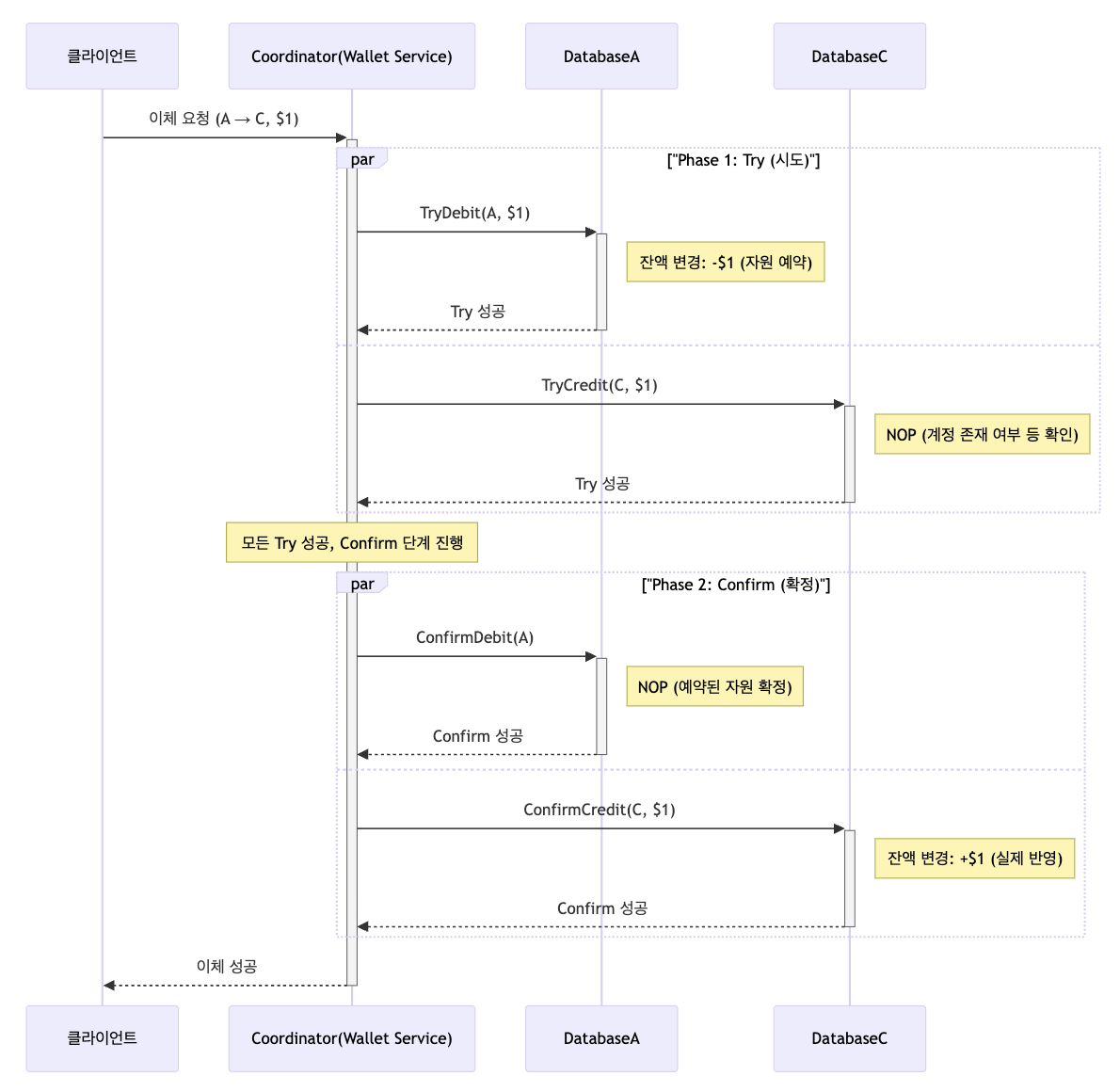
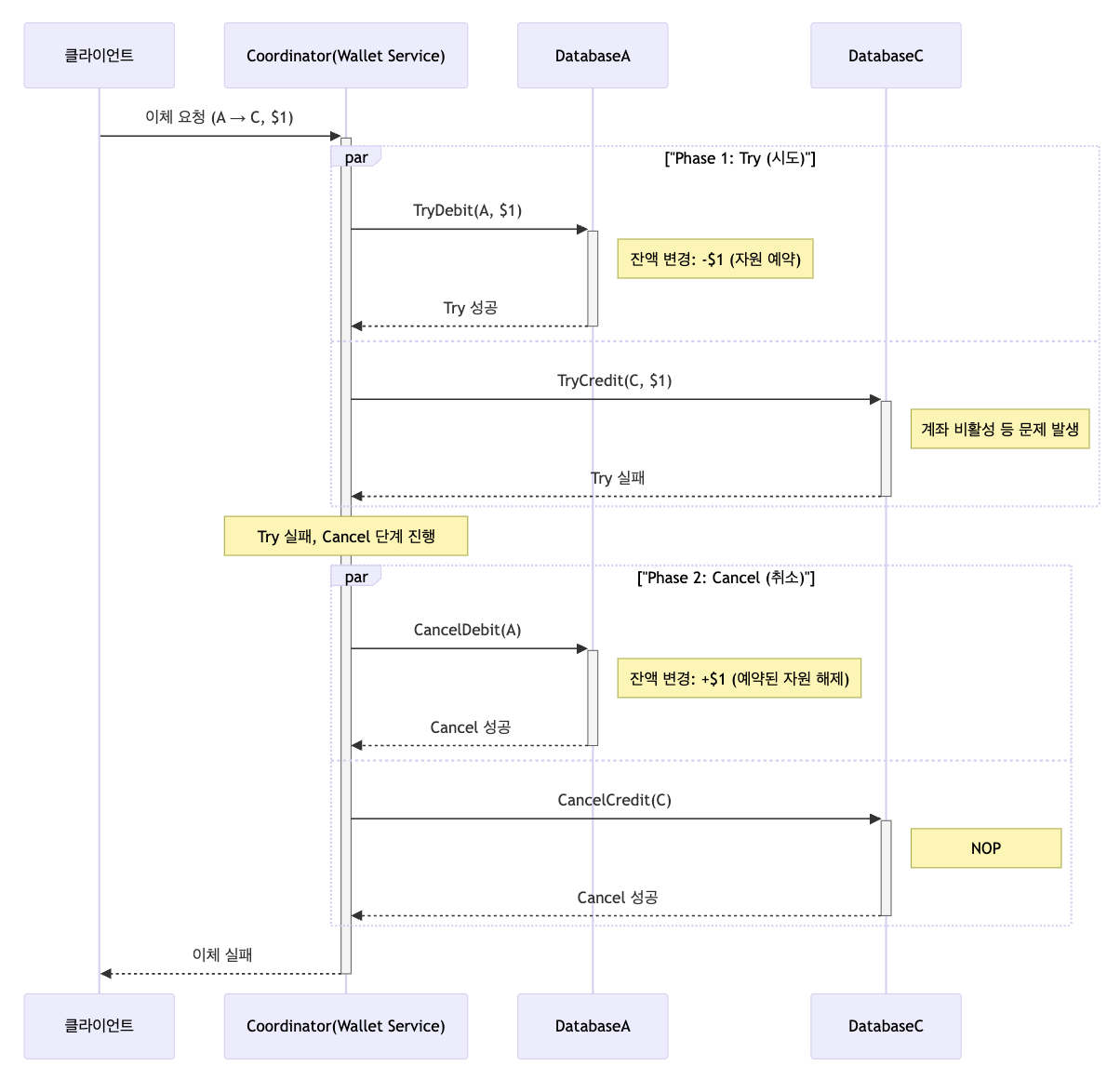
TC/C Digital Wallet Service Examples
| 단계 | 실행연산 | A | C |
|---|---|---|---|
| 1 | 시도 | 잔액 변경: -$1 | NOP(No Operation) |
| 2 | 확인 | NOP | 잔액 변경: +$1 |
| 3 | 취소 | 잔액 변경: +$1 | NOP |
Wallet Service 가 TC/C 의 Coordinator 이라 가정하자. 분산 트랜잭션이 시작될 때 계정 A 의 잔액은 1달러이고 C 는 0달러이다.
Try-Confirm:
Try-Cancel:
TC/C 는 보상 기반 분산 트랜잭션(distributed tx by compensation) 이라고도 부른다. 실행 취소(undo) 절차를 비지니스 로직으로 구현하므로 고수준 해법이며, 장점은 특정 데이터베이스에 구애받지 않는다. 단점은 분산 트랜잭션의 복잡성을 비지니스로직으로 풀어내야 한다는 것이다.
SAGA
Saga 는 분산 트랜잭션 문제를 해결하기 위한 MSA 에서의 사실상 표준이다.
개념은 다음과 같다.
- 모든 연산은 순서대로 정렬된다. 각 연산은 자기 데이터베이스에 독립 트랜잭션으로 실행된다.
- 연산은 첫 번째부터 마지막까지 순서대로 실행된다. 한 연산이 완료되면 다음 연산이 개시된다.
- 연산이 실패하면 전체 프로세스는 실패한 연산부터 맨 처음 연산까지 역순으로 보상 트랜잭션을 통해 롤백된다.
분산 조율(choreography)방식과 중앙 집중형 조율(orchestration) 방식이 존재한다. 분산 조율 방식은 서비스가 서로 비동기식으로 통신하기 때문에, 모든 서비스는 다른 서비스가 발생시킨 이벤트의 결과로 어떤 작업을 수행할지 정하기 위해 내부적으로 상태 기계(state machine) 를 유지해야한다. 일반적으로는 Orchestration 방식을 선호하며, 복잡한 상황을 잘 처리한다.
TC/C 랑 Saga 중에서는 지연 시간(latency) 요구사항에 따라 선택하면 된다.
- 지연 시간 요구사항이 없거나 덜 중요한 경우에는 Saga 를 선택한다.
- 지연 시간에 민감한 경우에는 TC/C 가 더 낫다. (병렬로 실행 가능하기 때문)
Event Sourcing: Proof of Accuracy, Reproducibility
전자 지갑은 '이체'가 가능하다. 전자 지갑은 정확성에 대한 엄격한 요건이 있기 때문에 데이터베이스가 제공하는 트랜잭션 보증(transactional guarantee) 이 필요하다. 또한 정확성 증명(Proof of Accuracy) 이 중요하다.
보통 정확성 증명은 트랜잭션이 완료된 후에 확인할 수 있으며, 내부 기록과 은행의 명세서를 비교를 통해 할 수 있다. 이를 토대로 History 테이블과 로그(Log)를 비교하는 설계 도 정확성 검증의 한 부분이라고 할 수 있을 것 같다.
하지만 이러한 조정(reconciliation)만으로는 데이터의 일관성이 깨졌다는 사실은 알 수 있지만 그 차이가 왜 발생했는지는 알기 힘들다. 따라서, 재현성(reproducibility) 을 갖춘 시스템을 설계하는 것이 중요하다.
즉, 처음부터 데이터를 재생하여 언제든지 과거 잔액을 재구성할 수 있는 시스템을 만드는 것이다.
이러한 재현성을 갖춘 시스템을 만들기 위해서는 Event Sourcing 이 주로 사용된다.
Digital Wallet Service 제공 업체도 감사를 받을 수 있다. 예를 들어 외부 감사(auditor)는 다음과 같은 까다로운 질문들을 던질 수 있다.
- 특정 시점의 계정 잔액을 알 수 있나요?
- 과거 및 현재 계정 잔액이 정확한지 어떻게 알 수 있나요?
- 코드 변경 후에도 시스템 로직이 올바른지는 어떻게 검증하나요?
이러한 질문에 체계적으로 답할 수 있는 설계 철학 중 하나는 Domain-Driven Design 에서 개발된 기법인 Event Sourcing 이다.
가상 면접 사례로 배우는 대규모 시스템 설계 기초2
Event Sourcing 은 문제의 근본 원인을 역추적하고 모든 연산을 감사하기 위한 좋은 도구이다. 이벤트 소싱 의 기본 아이디어 는 애플리케이션 상태의 모든 변경 사항을 이벤트 객체에 캡처하고, 이러한 이벤트 객체 자체가 애플리케이션 상태 자체와 동일한 수명 동안 적용된 순서대로 저장된다는 것이다.
이벤트 소싱에 중요한 4가지 용어는 다음과 같다.
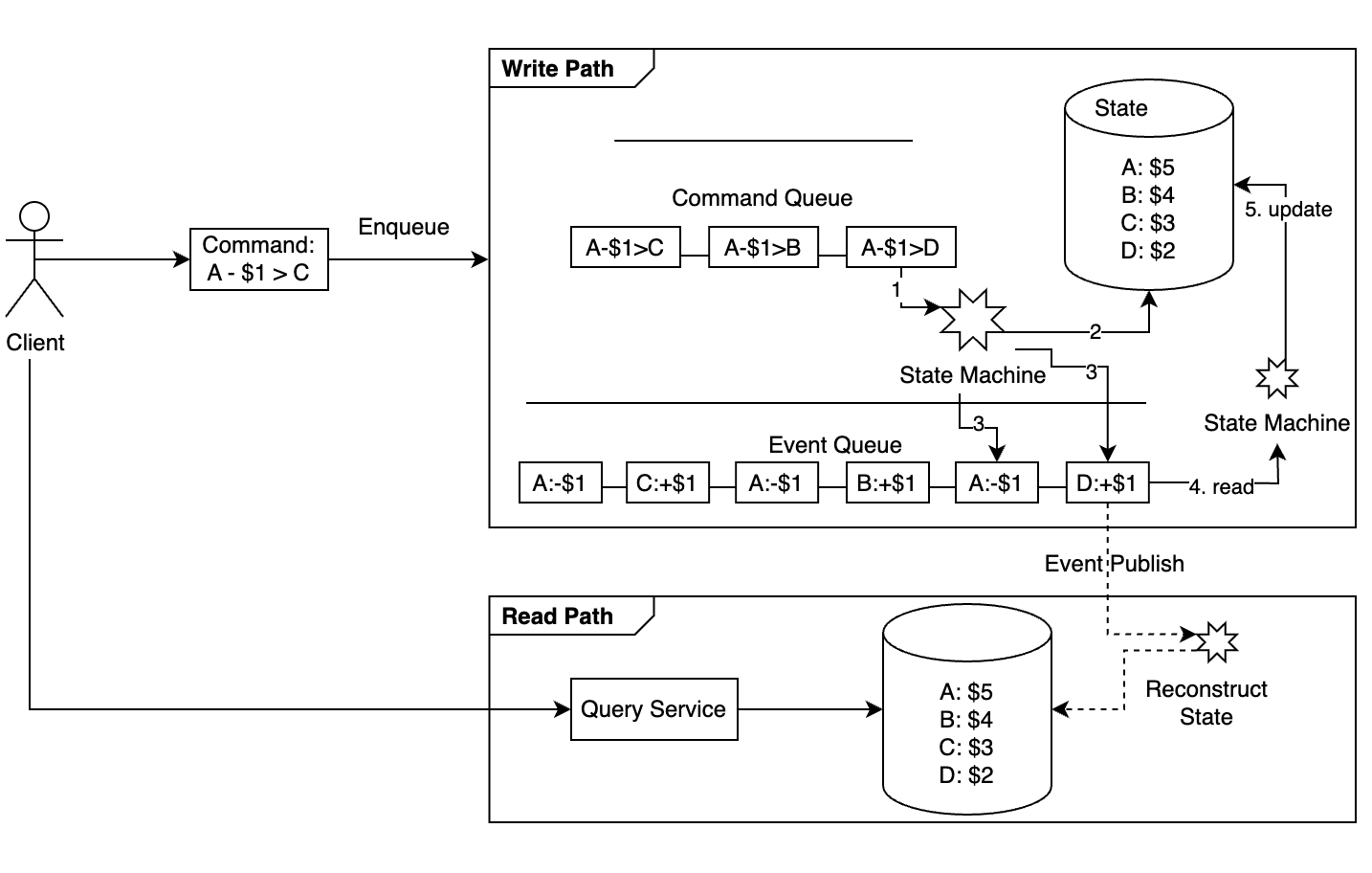
- 명령(command): 의도가 명확한 요청이며, 일반적으로 FIFO Queue 에 저장된다. 의도가 명확하지만 사실(fact)는 아니기 때문에 유효한 명령인지 검증해야 한다. 명령에는 무작위성이 포함될 수 있다. 하나의 명령으로 여러 이벤트가 만들어 질 수 있다.
- 이벤트(event): 명령 이행 결과는 이벤트이며, 이벤트는 검증된 사실(fact)이다. 이벤트는 과거에 실제로 있었던 일이며 결정론적(deterministic)이다. 이벤트 생성 과정에는 무작위성이 개입될 수 있어서 같은 명령이 항상 동일한 이벤트를 만들진 않는다. 이벤트는 명령 순서를 따라야 하므로 FIFO Queue 에 저장된다.
- 상태(state): 상태는 이벤트가 적용될 때 변경되는 내용이다.
- 상태 머신(state machine): 이벤트 소싱 프로세스를 구동하며, 크게 다음 2가지의 역할을 담당한다. 명령의 유효성을 검사하고 이벤트를 생성한다. 이벤트를 적용하여 상태를 갱신한다.
이벤트 소싱을 위한 상태 머신은 결정론적으로 동작해야 한다. 따라서 무작위성을 내포할 수 없고, I/O 를 통해 외부에서 무작위적 데이터를 읽거나 난수를 사용하는 것은 허용되지 않는다. 이벤트를 상테에 반영하는 것 또한 항상 같은 결과를 보장해야 한다.
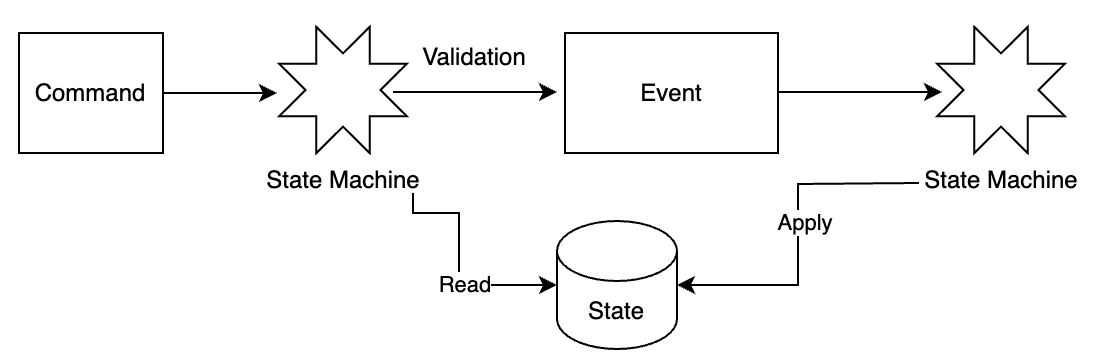
이벤트 소싱 프레임 워크 외부의 클라이언트가 상태(e.g 잔액)을 알기 위해서는 데이터베이스 읽기 전용 사본을 생성하는 것도 있지만 이벤트 소싱은 Command-Query Responsibility Separation, CQRS 를 사용한다.
CQRS 에서 상태 기록을 담당하는 상태 기계는 하나고, 읽기 전용 상태 기계는 여러개 있을 수 있다. 읽기 전용 상태 기계는 상태 뷰(view)를 만들고 query 에 이용된다. 예를 들어 특정한 기간 동안의 상태를 복원할 수도 있고, 이를 감사 기록에 활용할 수 있다.
읽기 전용 상태 기계는 실제 상태에 어느 정도 뒤쳐질 수 있으나 결국에는 같아지는 Eventual Consistency 모델을 따른다.
Links
- System Design Interviews Volume 2 - References
- Development of Further Patterns of Enterprise Application Architecture
- REST 기반의 간단한 분산 트랜잭션 구현 - 1편
- spring cloud rest tcc
- TCC - DTM
References
- System Design Interview Volume 2