MapReduce
architecture fp database mongodb designpattern
MapReduce
맵-리듀스(MapReduce)는 대규모 데이터 처리를 위한 프로그래밍 모델 및 처리 패러다임이다. 이 매커니즘은 많은 문서를 대상으로 읽기 전용(read only) 질의를 수행할 때 사용한다.
맵-리듀스는 큰 규모의 데이터 집합을 여러 노드에 분산하여 처리하고, 그 결과를 모으는 방식으로 동작한다. 이러한 처리는 두 단계로 나눠진다.
Workflow
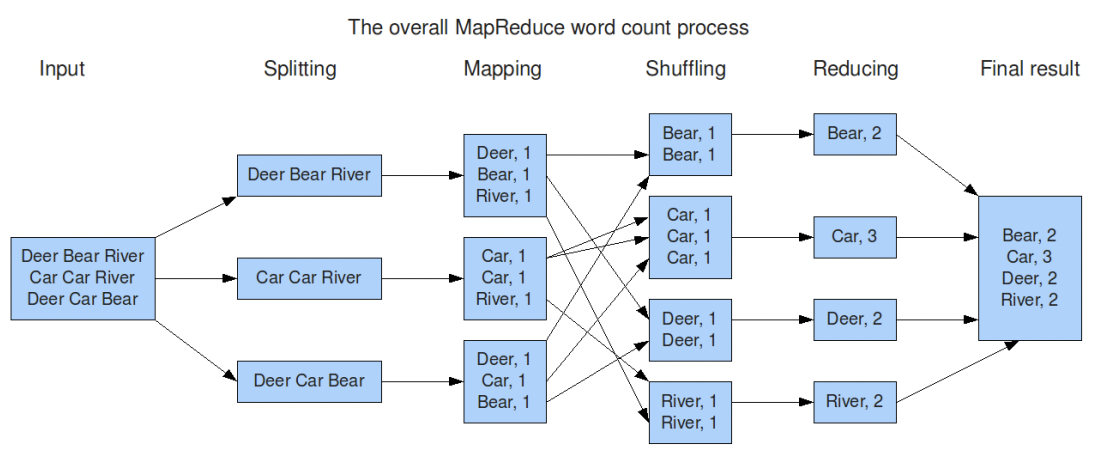
1. map(collect) 단계:
- 입력 데이터를 여러 개의 작은 조각으로 나눈다.
- 각각의 조각에 대해 사용자가 정의한 맵 함수를 적용하여 중간 결과를 생성한다.
- 중간 결과는 (키, 값) 쌍으로 표현된다.
2. reduce(fold, inject) 단계
- 맵 단계에서 생성된 중간 결과를 특정 기준에 따라 그룹화(키를 기준으로 그룹화)한다.
- 그룹화된 결과를 리듀스 함수에 적용하여 최종 결과를 생성한다.
Example
PostgreSQL:
SELECT date_trunc('month', observation_timestamp) AS observation_month, sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;
MongoDB Map-Reduce:
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals); // 2. 키, 값으로 방출
},
function reduce(key, value) { // 3. map 이 방출한 키-값 쌍을 키로 그룹화. 같은 키를 갖는(같은 연도와 월0 모든 키-값 쌍은 reduce 함수를 한 번 호출함.
return Array.sum(values);
},
{
query: { family: "Sharks" }, // 1. 상어 종만 거르기 위한 필터를 지정한다.
out: "monthlySharkReport" // 4. 최종 출력을 monthlyShartReport 컬렉션에 기록한다.
}
);
MongoDB map-reduce 함수 사용 시 제약사항:
- 순수 함수(pure function) 여야 한다. 즉, 입력으로 전달된 데이터만 사용해야하고 추가적인 데이터베이스 질의를 수행하면 안된다.
- 즉, 부수 효과(side effect) 가 없어야 한다.
Kotlin:
// 데이터 소스로 사용할 문장 목록
val sentences = listOf(
"MapReduce is a programming model",
"for processing and generating big data sets",
"with a parallel, distributed algorithm on a cluster",
"MapReduce can handle large amounts of data in parallel"
)
// Map 함수: 문장을 단어로 분리하여 (단어, 1) 형태의 Pair로 반환
fun mapFunction(sentence: String): List<Pair<String, Int>> {
val words = sentence.split(" ")
return words.map { word -> Pair(word, 1) }
}
// Reduce 함수: 동일한 키(단어)를 가진 Pair들을 합산하여 (단어, 누적된 카운트) 형태의 Pair로 반환
fun reduceFunction(pairs: List<Pair<String, Int>>): Map<String, Int> {
val resultMap = mutableMapOf<String, Int>()
for ((word, count) in pairs) {
resultMap[word] = resultMap.getOrDefault(word, 0) + count
}
return resultMap
}
fun main() {
// Map 단계
val mappedResults = sentences.flatMap { mapFunction(it) }
// Reduce 단계
val reducedResults = mappedResults.groupBy({ it.first }, { it.second })
.map { (word, counts) -> Pair(word, counts.sum()) }
// 결과 출력
reducedResults.forEach { println("${it.first}: ${it.second}") }
}
Links
References
- Designing Data-Intensive Applications / Martin Kleppmann / O'REILLY