Data Modeling
Analysis Workloads, Relationship Modeling, Schema Design Pattern
database mongodb designpattern
Data Modeling
데이터 모델링은 크게 4가지 단계를 거쳐 진행된다. 이번 내용은 MongoDB.local 2025 Seoul 에서 배운 내용을 정리한 것이다.
- 엔티티 식별, 속성 설명
- 워크로드 유형 분류 및 산정
- 관계 식별 및 수치화 내장 또는 참조 결정
- 스키마 최적화 안티패턴 회피
Workloads
워크로드 분석은 애플리케이션이 읽기 중심인지, 쓰기 중심인지, 가장 빈번한 작업은 무엇인지, 작업 빈도에 따른 쿼리 최적화는 어떤 엔티티를 위주로 해야할지 그리고 데이터의 크기 등을 파악하는 과정이다.
예를 들어 활성 사용자가 100,000명을 보유중이라고 할때 다음과 같은 질문들을 던져 인사이트를 도출할 수 있다.
- 예약 생성 작업은 얼마나 자주 수행될까요?
- 매일 몇 개의 도서 대출 기록이 생성될까요?
- 매일 몇 개의 예약이 만료될까요?
- 도서 상세 정보 조회 작업은 얼마나 자주 수행될까요?
- 5년동안 도서 수의 증가량은?
Workload 가 Data Modeling 을 결정한다.
Relationships
관계 모델링에서는 다음과 같은 질문들을 던져 관계 모델링을 할 수 있다.
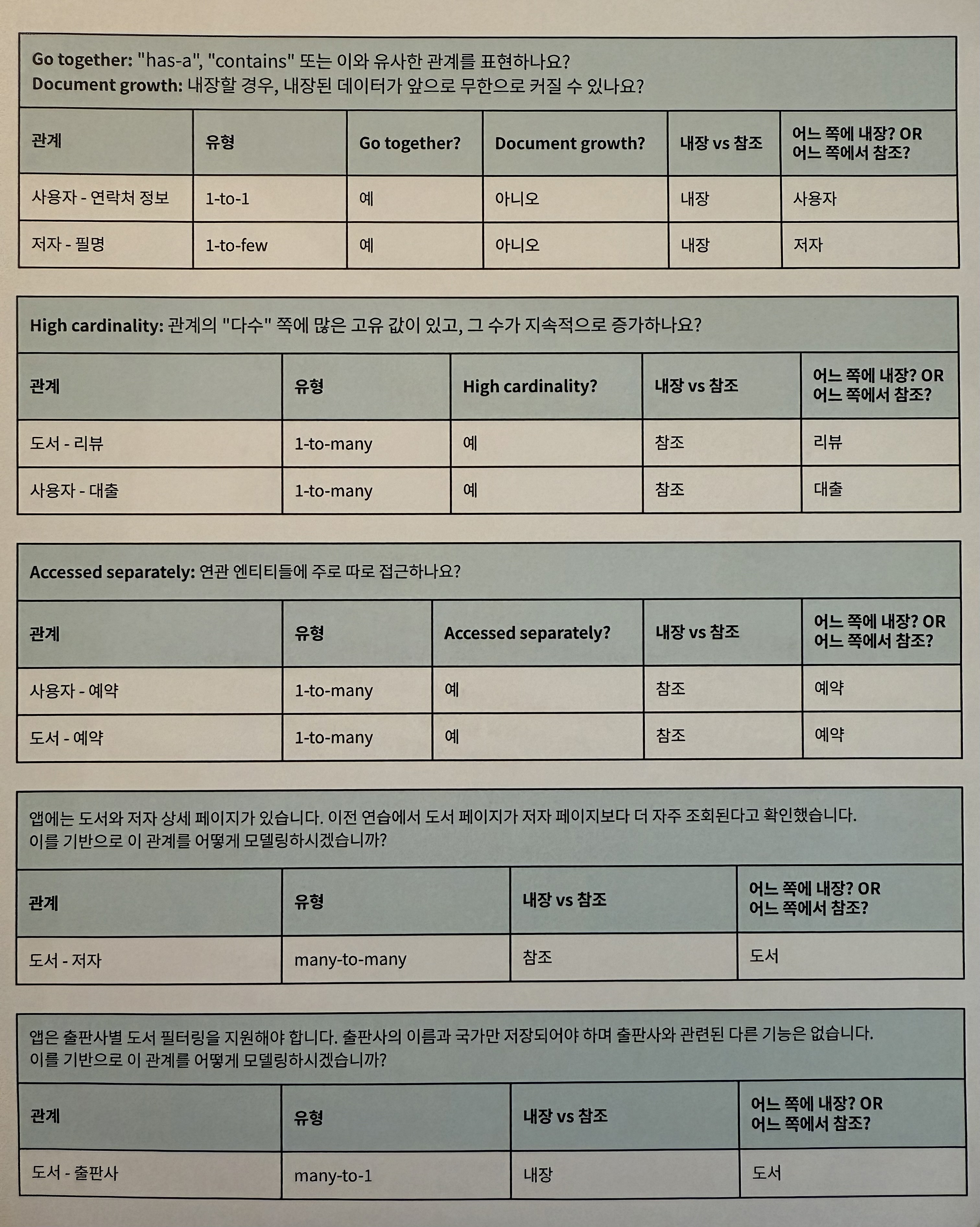 MongoDB.local 2025 Seoul
MongoDB.local 2025 Seoul
| Type | Description |
|---|---|
| One to One | 부모 엔티티에 임베드한다. 예외로는 문서가 비대해져 메모리 또는 대역폭 사용량이 높아지는 경우 임베드를 사용하면 안된다. |
| One to Few | One 쪽에 내장한다. 예외로는 few 가 단독으로 자주 액세스 되는 경우와 문서가 비대해져 메모리 또는 대역폭 사용량이 높아지는 경우 임베드를 사용하면 안된다. |
| One to Many (중간 cardinality) | 가장 중요한 것은 함께 액세스되는 경우 함께 저장(자주 액세스 되는 곳)하는 것이다. 모르겠는 경우에는 별도 컬렉션에 배치하고 참조하도록 하면 된다. |
| One to Zillions (제한 없는 증가) | Many 쪽에 참조한다. |
| Many to Many | 쿼리 빈도가 높은 쪽에 참조를 사용한다. 예외로는 참조가 있는 배열이 무제한으로 커질 수 있는 경우, 반대쪽에서 참조해야 한다. |
Core MongoDB Design Concepts
| Type | Description |
|---|---|
| Embedding | 관계 및 복잡한 계층 구조를 표현하기 위해 다른 문서 내에 문서를 저장할 수 있다. JOIN 을 피하여 성능을 높일 수 있다. |
| Arrays | 문서의 필드 값은 배열일 수 있으며, 이 배열 자체가 문서가 될 수 있다. 배열은 다양한 데이터 모델링 옵션을 제공하며, 특히 1:1 및 N:M 관계에 대한 옵션을 제공하여 관련 데이터를 함께 저장할 수 있다. |
| Polymorphism | 동일한 컬렉션 내에 서로 다른 필드를 가진 문서를 저장할 수 있다. 다형성을 사용하면 유사한 유형의 데이터를 동일한 컬렉션에 저장하고 함께 검색할 수 있다. 또한 다형성을 사용하면 서로 다른 버전의 스키마가 공존할 수 있기 때문에, 다운타임 없이 스키마를 업데이트 할 수 있다. |
Schema Validation
스키마 유효성 검증(Schema Validation)은 데이터 무결성 유지를 위해 가급적 권장된다. 컬렉션 단위로 정의하며, 애플리케이션이 아닌 데이터베이스 수준에서 동작한다.
db.createCollection("students", {
validator: {
$jsonSchema: {
bsonType: "object",
title: "Student Object Validation",
required: [ "address", "major", "name", "year" ],
properties: {
name: {
bsonType: "string",
description: "'name' must be a string and is required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
description: "'year' must be an integer in [ 2017, 3017 ] and is required"
},
gpa: {
bsonType: [ "double" ],
description: "'gpa' must be a double if the field exists"
}
}
}
}
} )
Schema Design Patterns
- Extended Reference(확장된 참조): 빈번한 Operation 의 Join 횟수를 최소화 하기 위한 내장과 참조 사이의 중간 솔루션이다. 자주 Join 해야하는 별도의 컬렉션에 데이터가 저장된 경우 사용한다.
- Computed(계산된): 값을 미리 계산하고 저장하여 읽기 성능을 향상한다. 데이터 검색 시 계산 작업이 자주 수행되는 경우를 처리한다. 계산이 필요한 문서에서 읽기 비율이 높은 경우에 사용한다.