Vector Embedding
Vector Embedding
Vector 는 크기와 방향을 동시에 가지는 수학적 구조를 의미한다.
개발자 입장에서는 Vector 를 숫자 값을 포함하는 Dynamic Array 로 생각하면 더 쉽다.
vector = [0,-2,...4]
복잡한 대상(단어, 이미지, 사용자, 상품 등)을 수치 벡터로 바꾼 것을 Embedding Vector 라고 하고, 이 벡터는 머신러닝이나 검색 시스템, 오디어/이미지 검색, 추천 시스템, 자연어 처리(NLP)에서 유사성을 비교하거나 입력값으로 쓰이기 위해 사용된다. 많은 최신 임베딩 모델은 레이블이 지정된 대량의 데이터를 신경망에 전달하여 구축된다. (참고. Tensorflow Projector, Word2vec)
예를 들어 "고양이"라는 단어를 [0.12, -0.88, 0.45, ..., 0.77] 같은 벡터로 변환하고 저장한다.
이렇게 변환된 벡터를 통해 유사한 의미를 가진 데이터끼리 가까운 벡터로 표현된다.
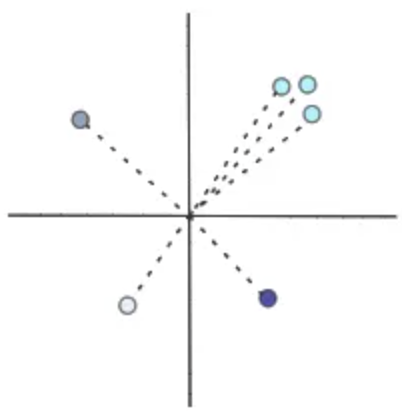
서로 가까이 있는 단어는 의미적으로 유사한 반면, 멀리 있는 단어는 의미적으로 서로 다르다. 이것이 바로 벡터에 의미를 부여하는 것이다. 벡터 공간의 다른 벡터들과의 관계는 임베딩 모델이 학습된 도메인을 어떻게 "이해"하느냐에 따라 달라진다.
Geographic Information Systems 의 벡터는 현실 세계를 지도 위에 표현하기 위한 단순한 공간 구조이고, 추천 시스템의 벡터는 대상의 특징을 고차원 수학 공간에 표현한 것이다.
Vector Space Model 을 구현한 대표적인 소프트웨어로는 텍스트 검색 엔진 라이브러리인 Apache Lucene 과 Lucene 을 기반으로 한 OpenSearch 등이 있다.