EVENTUAL CONSISTENCY
- Essence of Eventual Consistency
- Consistency Model Spectrum
- Why Eventual Consistency Matters
- Conflict Resolution Strategies
- Implementation Patterns
- Exactly-Once Semantics
- Two-Phase Commit vs Eventual Consistency
- Practical Q&A
- Common Pitfalls
- Links
- References
Essence of Eventual Consistency
Eventual Consistency 는 분산 시스템에서 가용성(Availability) 과 분할 내성(Partition Tolerance) 을 확보하면서도 데이터 일관성을 포기하지 않기 위한 일관성 모델이다.
Werner Vogels(Amazon CTO)는 2008년 ACM Queue 에 발표한 "Eventually Consistent" 에서 이를 다음과 같이 정의했다.
"The storage system guarantees that if no new updates are made to the object, eventually all accesses will return the last updated value."
핵심 정의는 단순하다. 모든 업데이트가 중단되면, 충분한 시간이 지난 뒤 모든 복제본(replica)이 동일한 값으로 수렴한다. 이 수렴이 유효하려면 두 가지 조건이 필요하다.
- 모든 업데이트가 결국 모든 복제본에 전달된다.
- 충돌 해결 프로세스가 결합 법칙(associative), 교환 법칙(commutative), 멱등성(idempotent)을 만족한다.
이 모델은 CAP 에서 출발한다. CAP 정리에서 주의할 점은, 이것이 시스템의 영구적인 속성이 아니라 Network Partition 이 발생한 동안 의 행동에 관한 것이라는 점이다. Partition 이 없는 정상 상태에서는 Consistency 와 Availability 를 모두 확보할 수 있다. 그러나 분산 시스템에서 Network Partition 은 피할 수 없고, 그 상황에서 Availability 를 포기하는 것은 현실적이지 않다. Strong Consistency 를 고수하면 2PC 같은 blocking protocol 이 필요해지고, 이는 성능 저하와 단일 장애 지점을 만든다.
Eventual Consistency 는 "일관성을 포기하는 것"이 아니라, "일관성이 달성되는 시점을 늦추는 대신 가용성과 성능을 확보하는 트레이드오프"이다.
분산 시스템의 속성은 Safety ("나쁜 일이 일어나지 않는다")와 Liveness ("좋은 일이 결국 일어난다")로 구분된다. Eventual Consistency 는 본질적으로 Liveness 속성이다 — "모든 복제본이 결국 수렴한다"는 보장이다. 더 강한 일관성 모델은 수렴 이전에 관찰할 수 있는 상태를 제한하는 Safety 속성을 추가한다.
BASE Semantics
Eventual Consistency 를 채택한 시스템은 BASE 의미론을 따른다. ACID 와 대비되는 개념이다.
| ACID | BASE |
|---|---|
| Atomicity | Basically Available: 부분 장애에도 시스템은 동작한다 |
| Consistency | Soft State: 외부 입력 없이도 상태가 변할 수 있다 (비동기 복제) |
| Isolation | Eventual Consistency: 충분한 시간이 지나면 모든 복제본이 수렴한다 |
| Durability | - |
Consistency Model Spectrum
일관성 모델은 하나의 스펙트럼 위에 놓여 있다. Strong Consistency 에서 Eventual Consistency 까지, 보장 수준과 성능·가용성 사이에 트레이드오프가 존재한다.
Linearizability → Sequential Consistency → Causal Consistency → Eventual Consistency
(strongest) (weakest)
| Model | 보장 수준 | 성능 | 가용성 | 대표 시스템 |
|---|---|---|---|---|
| Linearizability | 모든 연산이 실시간 순서 보장 (linearization point) | 낮음 | 낮음 | Spanner, CockroachDB |
| Sequential Consistency | 프로세스별 순서 보장, 실시간 순서는 미보장 | 중간 | 중간 | ZooKeeper (기본 읽기) |
| Causal Consistency | 인과 관계가 있는 연산의 순서 보장 | 높음 | 높음 | MongoDB (causal session) |
| Eventual Consistency | 최종 수렴만 보장, 순서 보장 없음 | 매우 높음 | 매우 높음 | DynamoDB, Cassandra |
Linearizability (Herlihy & Wing, 1990)는 각 연산이 호출(invocation)과 응답(response) 사이의 어떤 시점에서 원자적으로 효과를 가지는 것처럼 보이는 것이다. CAP 정리에서 말하는 "Consistency" 가 바로 이 Linearizability 이다. ACID 의 Consistency 와는 다른 개념이다.
Client-Centric Consistency Models
Vogels 는 Eventual Consistency 의 실용적 변형으로 Client-Centric Consistency Models 를 정의했다.
| Model | 정의 |
|---|---|
| Causal Consistency | 프로세스 A 가 데이터를 갱신하고 프로세스 B 에 통지하면, B 는 갱신된 값을 본다. 인과 관계가 없는 프로세스 C 는 일반적인 Eventual Consistency 규칙을 따른다 |
| Read-Your-Writes | 프로세스 A 가 데이터를 갱신한 후, A 는 항상 갱신된 값을 본다. 이전 값을 보는 일은 없다 |
| Session Consistency | Session 컨텍스트 내에서의 Read-Your-Writes. 실무에서 가장 많이 쓰이는 모델이다 |
| Monotonic Reads | 프로세스가 값을 읽은 후, 이후 읽기는 같거나 더 최신의 값을 반환한다. 읽기가 "뒤로 가는" 일은 없다 |
| Monotonic Writes | 같은 프로세스의 쓰기는 시스템이 직렬화한다. 선행 쓰기가 완료된 후에 후행 쓰기가 처리된다 |
Vogels 는 실무 관점에서 Monotonic Reads 와 Read-Your-Writes 가 가장 바람직한 보장이라고 언급했다.
Strong Eventual Consistency
Strong Eventual Consistency(SEC) 는 Eventual Consistency 의 강화된 변형이다. SEC 는 다음 두 가지를 보장한다.
- 동일한 업데이트 집합을 수신한 두 복제본은 즉시 동일한 상태에 도달한다 (추가적인 충돌 해결이 불필요).
- 업데이트 수신 순서에 관계없이 결과가 동일하다.
CRDT 가 SEC 를 수학적으로 보장하는 대표적인 데이터 구조이다. CRDT 는 교환 법칙(commutativity), 결합 법칙(associativity), 멱등성(idempotency)을 만족하도록 설계되어, 충돌이라는 개념 자체가 존재하지 않는다.
PACELC Theorem
CAP 정리는 Partition 상황에서의 트레이드오프만 다룬다. Daniel Abadi(Yale, 2012)는 PACELC 정리를 제안하여 정상 운영 시의 트레이드오프까지 확장했다.
Partition 발생 시 → Availability 와 Consistency 중 선택 Else (정상 운영 시) → Latency 와 Consistency 중 선택
Abadi 의 핵심 주장은 이렇다: "Network Partition 은 드문 상황이지만, Latency 와 Consistency 사이의 트레이드오프는 시스템이 동작하는 모든 순간 에 존재한다."
| System | 분류 | 설명 |
|---|---|---|
| Cassandra, DynamoDB | PA/EL | Partition 시 가용성, 정상 시 낮은 지연 |
| MongoDB (primary reads) | PA/EC | Partition 시 가용성, 정상 시 일관성 (secondary reads 시 stale 가능) |
| Traditional RDBMS | PC/EC | 항상 일관성 우선 |
Why Eventual Consistency Matters
Availability over Strong Consistency
분산 시스템에서 Strong Consistency 를 유지하려면 모든 노드가 합의(consensus)에 도달해야 한다. 이 과정에서 다음과 같은 비용이 발생한다.
Client ──request──▶ Node A
│
├── PREPARE ──▶ Node B
├── PREPARE ──▶ Node C
│
◀── ACK ────── Node B
◀── ACK ────── Node C
│
├── COMMIT ──▶ Node B
├── COMMIT ──▶ Node C
│
Client ◀──response── Node A
⏱ 최소 2 RTT(Round-Trip Time) + fsync 비용
대륙 간 왕복 지연은 100~300ms 에 달한다. 지리적으로 분산된 3개 복제본을 가진 시스템에서의 쓰기 지연은 \(2 \times \max(\text{RTT to all replicas})\) 이다. Eventual Consistency 모델을 채택하면 로컬 노드에서 즉시 쓰기를 완료하고(~1ms), 복제는 비동기로 처리할 수 있다.
Microservices and Polyglot Persistence
Polyglot Persistence 구조에서는 각 마이크로서비스가 자율적인 저장소를 소유한다. 서비스 간 데이터 정합성을 2PC 로 묶으면 서비스의 독립성이 침해되고, NoSQL 저장소처럼 2PC 를 지원하지 않는 경우도 많다.
따라서 마이크로서비스 아키텍처에서는 각 서비스가 로컬 트랜잭션을 독립적으로 수행하고, 비동기 이벤트(Async Event) 를 통해 서비스 간 일관성을 달성하는 Eventual Consistency 가 사실상 표준이다.
Real-World Systems
| System | Eventual Consistency 활용 방식 |
|---|---|
| DNS | TTL 기반 캐싱으로 업데이트 전파. 전파 중 stale 레코드가 서빙된다 |
| Amazon DynamoDB | Sloppy quorum + hinted handoff. 연산 단위로 일관성 수준 조정 가능 |
| Apache Cassandra | Tunable consistency level (ONE ~ ALL). 기본값은 Eventual Consistency |
| CDN | Edge 노드에 캐싱된 콘텐츠는 TTL 만료 전까지 stale 상태일 수 있다 |
Conflict Resolution Strategies
Eventual Consistency 환경에서 여러 복제본이 동시에 수정되면 충돌(conflict) 이 발생할 수 있다. 정합성을 이야기할 때는 두 층위를 구분해야 한다.
- Replica Convergence: 여러 복제본이 시간이 지나면 같은 값으로 수렴하는가?
- Business Invariant: 잔액 음수 금지, 재고 0 미만 금지 같은 업무 규칙(불변식)을 항상 지키는가?
Eventual Consistency 는 Replica Convergence 는 잘 달성하지만, Business Invariant 는 충돌 해결만으로는 100% 보장하지 못하는 경우가 많아서 일부는 coordination(합의)이 필요하다.
Last-Writer-Wins (LWW)
가장 단순한 전략이다. 각 쓰기에 타임스탬프를 부여하고, 충돌 시 가장 늦은 타임스탬프의 값을 채택한다.
Node A: set(key, "v1", t=100)
Node B: set(key, "v2", t=102)
─── 동기화 후 ───
Result: key = "v2" (t=102 > t=100)
장점: 구현이 단순하고 자동으로 수렴한다.
단점:
- 시스템 클록 동기화에 의존한다. 분산 환경에서 클록 동기화는 어렵고 비용이 크다.
- 의미상 "최종"이 아닌 값이 채택될 수 있다. 예를 들어 사용자 A 가 더 의미 있는 변경을 했더라도 클록이 뒤처지면 무시된다.
- 데이터 손실이 발생할 수 있다 (concurrent write 중 하나는 무조건 버려진다).
Cassandra, DynamoDB 가 기본 충돌 해결로 LWW 를 사용한다.
Vector Clocks and Causal Ordering
LWW 의 물리적 클록 의존 문제를 해결하기 위해 Vector Clock 을 사용할 수 있다. Lamport(1978)의 Logical Clock 을 확장한 것으로, 각 노드가 모든 노드의 카운터를 벡터로 유지한다.
Node A: [A:2, B:0, C:0] ← A가 2번 이벤트 발생
Node B: [A:1, B:3, C:0] ← B가 A의 1번 이벤트를 수신한 뒤 3번 이벤트 발생
Node C: [A:1, B:2, C:1] ← C가 A의 1번, B의 2번 이벤트를 수신
인과성 판별:
- \(V(a) < V(b)\) (모든 성분이 \(\leq\), 최소 하나가 \(<\)) → a 가 b 에 선행(happened-before)
- \(V(a) \nless V(b)\) 이고 \(V(b) \nless V(a)\) → 두 이벤트는 동시적(concurrent) → 충돌
Vector Clock 으로 동시적 이벤트를 감지하면, 애플리케이션이 도메인 로직에 맞게 병합할 수 있다. Amazon Dynamo(2007)가 이 방식을 사용했다.
제약사항: 저장 공간이 노드 수에 비례하여 \(O(n)\) 으로 증가하며, 모든 메시지에 벡터를 포함해야 하므로 노드가 빈번하게 변경되는 환경에서는 부담이 된다.
Quorum-based Eventual Consistency
Quorum 은 모든 복제본의 응답을 기다리지 않고 정족수(Quorum) 만 확보하면 되는 복제 일관성 전략이다.
\[W + R > N\]- \(N\): 전체 복제본 수
- \(W\): 쓰기 시 확인 응답이 필요한 복제본 수
- \(R\): 읽기 시 확인 응답이 필요한 복제본 수
이 조건을 만족하면 읽기와 쓰기가 반드시 하나 이상의 최신 복제본을 포함하게 된다.
트레이드오프:
| 설정 | 특성 |
|---|---|
| W=N, R=1 | 쓰기 느림, 읽기 빠름 |
| W=1, R=N | 쓰기 빠름, 읽기 느림 |
| W=⌈(N+1)/2⌉, R=⌈(N+1)/2⌉ | 균형 설정 |
주의: \(R + W > N\) 은 Quorum 겹침을 보장하지만, 이것만으로 Linearizability 가 보장되지는 않는다. Concurrent write 에서의 LWW 타임스탬프 충돌, Hinted Handoff, Clock skew 등이 여전히 문제가 될 수 있다.
Sloppy Quorum and Hinted Handoff
Sloppy Quorum 은 지정된 복제본 노드가 아닌 다른 가용 노드에 임시로 쓰기를 허용하는 방식이다. 복제본 노드가 일시적으로 불가용할 때도 쓰기를 차단하지 않는다. Sloppy Quorum 은 표준 Quorum 의 \(W + R > N\) 겹침 보장을 희생하여 가용성을 높인 변형이다. 즉, 임시 노드에 쓰여진 데이터는 원래의 지정 복제본이 아니므로 읽기 Quorum 과 겹치지 않을 수 있다.
Hinted Handoff 는 Sloppy Quorum 의 후속 과정이다.
정상 상태: Client ──write──▶ Node A, B, C (지정 복제본)
Node C 장애: Client ──write──▶ Node A, B, D (D가 임시 대체)
│
hint 저장: "이 데이터는 C 의 것"
│
Node C 복구 ◀── hint 전달 ──── D
DynamoDB 와 Cassandra 가 이 방식을 사용한다. 가용성을 극대화하지만, hint 가 전달되기 전에는 stale read 가 발생할 수 있다.
Conflict-Free Replicated Data Types (CRDT)
CRDT 는 수학적 속성(교환 법칙, 결합 법칙, 멱등성)을 통해 충돌 자체를 원천적으로 방지하는 데이터 구조이다. Shapiro et al.(2011)에 의해 공식 정의되었으며, Strong Eventual Consistency(SEC) 를 보장한다.
두 가지 유형:
- State-based CRDTs (CvRDTs): 전체 상태를 전송하고 join-semilattice 로 병합한다. Gossip protocol 만 있으면 동작한다.
- Operation-based CRDTs (CmRDTs): 연산을 전송한다. Causal delivery 와 교환 법칙이 필요하다.
주요 CRDT 데이터 구조:
| 유형 | 설명 | 동작 원리 |
|---|---|---|
| G-Counter | 증가만 가능한 카운터 | 각 복제본이 자신의 카운터를 벡터로 유지. 값 = 전체 합. Merge = element-wise max |
| PN-Counter | 증가/감소 가능한 카운터 (음수 가능) | G-Counter 2개 (P: 증가용, N: 감소용). 값 = sum(P) - sum(N) |
| OR-Set | 추가/삭제 가능한 집합 | 각 원소에 고유 ID 태깅. Remove 는 관찰된 ID 만 제거. Add-wins on concurrent add/remove |
| LWW-Register | 단일 값 레지스터 | 각 업데이트에 타임스탬프 부여. 가장 높은 타임스탬프가 merge 시 승리 |
실무 사용 사례:
- Redis Enterprise: Multi-master geo-replication 에 CRDT 사용
- Riak: 최초의 CRDT 지원 데이터베이스 중 하나 (2013)
- Apple Notes: 기기 간 오프라인 편집 동기화에 CRDT 사용
제약사항: 모든 비즈니스 로직을 CRDT 로 표현할 수 있는 것은 아니다. 금융 거래, 독점 리소스 할당 같이 즉각적인 일관성이 필요한 시나리오에서는 CRDT 가 적합하지 않다.
Application-level Merge
충돌 발생 시 도메인 로직을 이용해 병합하는 방식이다. 시스템이 자동으로 해결할 수 없는 의미론적(semantic) 충돌을 처리할 때 사용된다.
예시: 두 명의 사용자가 동시에 같은 게시글을 수정한 경우
- 수정 시간 + 사용자 우선순위로 병합
- 또는 양쪽 변경을 모두 보존하고 사용자에게 수동 병합을 요청 (Git 의 merge conflict 와 유사)
Riak 은 sibling 으로 충돌 버전을 모두 보존하고, 애플리케이션이 읽기 시점에 해결하도록 한다.
Implementation Patterns
Compensating Transaction
보상 트랜잭션(Compensating Transaction) 은 특정 작업이 실패했을 때 이전 작업 단계의 결과를 실행 취소하기 위한 트랜잭션이다.
Eventual Consistency 환경에서 여러 서비스에 걸친 비즈니스 트랜잭션은 각 서비스의 로컬 트랜잭션으로 분리되고, 일관성이 달라진 부분은 보상 트랜잭션으로 맞춘다.
Choreography 방식 예시 (Saga 패턴 참고):
주문 서비스 재고 서비스 결제 서비스
│ │ │
├── 주문 생성 ──────▶│ │
│ ├── 재고 차감 ──────▶│
│ │ ├── 결제 처리
│ │ │
│ │ ✗ 결제 실패
│ │ │
│ ◀── 재고 복원 ◀──────┤ (보상 이벤트)
◀── 주문 취소 ◀─────┤ │ (보상 이벤트)
│ │ │
▼ 최종 상태: 일관성 회복 ▼
주요 고려사항:
- 보상 트랜잭션은 원래 작업의 정확히 반대 순서로 실행할 필요는 없으며, 일부 취소 단계를 동시에 수행할 수 있다.
- 보상 트랜잭션은 반드시 멱등(idempotent)이고 재시도 가능(retryable)하게 설계해야 한다.
- 보상 트랜잭션 자체가 실패하면? → 재시도 패턴을 적용하고, 최대 재시도 후에도 실패하면 Dead Letter Queue(DLQ)로 보내 수동 조사한다.
Saga 패턴이 보상 트랜잭션을 체계적으로 관리하는 대표적인 패턴이다.
Transactional Outbox
마이크로서비스가 데이터베이스를 갱신하면서 동시에 이벤트를 발행해야 할 때, 두 연산이 독립적으로 실패할 수 있는 Dual-Write Problem 이 발생한다.
Transactional Outbox 패턴은 이 문제를 해결한다.
┌─────────────────────────────────────────┐
│ 단일 DB 트랜잭션 (ACID) │
│ │
│ 1. Business Table 갱신 │
│ 2. Outbox Table 에 이벤트 기록 │
│ │
└─────────────────────────────────────────┘
│
┌──────────┴──────────┐
▼ ▼
Polling Publisher CDC (Debezium)
│ │
▼ ▼
┌─────────────────────────────┐
│ Message Broker (Kafka) │
└─────────────────────────────┘
비즈니스 데이터와 이벤트를 같은 ACID 트랜잭션으로 기록하고, 별도 프로세스가 Outbox 를 읽어 메시지 브로커에 발행한다.
| 접근 방식 | 장점 | 단점 |
|---|---|---|
| Polling | 어떤 DB 에서든 동작, 구현이 단순 | 지연이 높고, DB 스캔 부하 발생 |
| CDC (Debezium) | 거의 실시간, 낮은 오버헤드, 장애 복구 자동화 | DB CDC 지원 필요, 추가 인프라 |
Asynchronous Messaging with Message Queue
메시징이란 프로그램이 서로를 직접 호출하지 않고 메시지로 데이터를 전송하여 통신하는 것이다. 큐잉은 메시지가 저장소의 큐에 배치되어 프로그램이 서로 다른 속도와 시간, 다른 위치에서 독립적으로 실행될 수 있도록 하는 것이다.
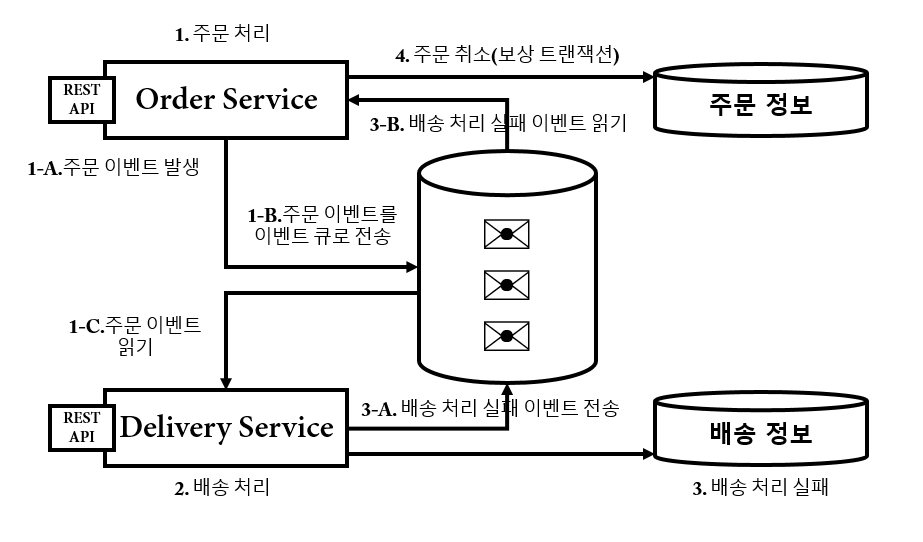
Message Queue 를 활용한 비동기 이벤트 처리는 Eventual Consistency 를 달성하는 가장 일반적인 방법이다. 핵심은 로컬 트랜잭션과 메시지 발행의 원자성을 보장하는 것이다.
Idempotency Design
Eventual Consistency 환경에서 메시지는 네트워크 장애, 재시도 등으로 인해 중복 수신될 수 있다. 이중 처리를 방지하려면 멱등성(Idempotency) 설계가 필수적이다.
실무 공식은 다음과 같다.
At-Least-Once Delivery + Idempotent Consumer = Effectively Exactly-Once
핵심 기법:
- Idempotency Key: 클라이언트가 요청마다 고유한 키(UUID 등)를 부여하고, 서버는 이 키를 기반으로 중복 요청을 식별한다.
- Inbox Pattern (Deduplication Table): 처리 완료된 이벤트 ID 를 별도 테이블에 저장하고, 수신 시 중복 여부를 확인한다. 비즈니스 로직과 ID 기록이 같은 트랜잭션 안에서 실행되어야 한다.
- Optimistic Locking: 버전 번호를 활용하여 동시 수정을 감지하고, 충돌 시 재시도한다.
자연스럽게 멱등한 연산(예: "잔액을 100으로 설정")은 별도 메커니즘이 필요 없다. 비멱등 연산(예: "잔액에 10을 추가")에서 Inbox Pattern 이 필수적이다.
Exactly-Once Semantics
이벤트 드리븐 아키텍처에서 Exactly-once 처리는 최고 난이도의 보장 조건 중 하나이다. 현실에서는 "실질적으로 한 번만 처리된 것처럼 보이는(at-least-once with idempotency or deduplication)" 구현이 일반적이다.
Exactly-once 처리를 구현하려면 세 가지 조건을 모두 만족해야 한다.
- 메시지 중복 수신 방지: 네트워크 이슈로 메시지가 재전송되더라도, 수신 측에서는 한 번만 처리해야 한다.
- 처리 결과의 중복 반영 방지: 예를 들어 Kafka 에서 메시지를 두 번 consume 하더라도, DB 에 한 번만 insert 되어야 한다.
- 처리 성공 여부의 안정적 커밋: 메시지 처리 후 consumer offset 과 DB 상태를 일관성 있게 commit 해야 한다.
Practical Approaches
At-least-once + Idempotent Consumer:
Consumer ──▶ 이벤트 수신
│
▼
Dedup Table 조회 ──▶ 이미 처리됨? ──▶ Skip
│
▼ (미처리)
비즈니스 로직 실행
│
▼
Dedup Table 기록 + Offset Commit (단일 트랜잭션)
삼중 방어 전략:
| 계층 | 기법 | 설명 |
|---|---|---|
| Broker | Idempotent Producer | Kafka enable.idempotence=true 로 Producer 레벨 중복 방지 |
| Consumer | Inbox Pattern | 메시지 ID 추적으로 Consumer 레벨 중복 처리 방지 |
| Application | 자연적 멱등성 설계 | 가능한 경우 연산 자체를 멱등하게 설계 |
Kafka Transactional Producer/Consumer:
Kafka 의 Transactional API 를 사용하면 produce-consume-produce 패턴에서 exactly-once semantics 를 달성할 수 있다. 단, 이는 Kafka 생태계 내부에서만 유효하며, 외부 시스템(DB, 이메일 등)과의 통합에서는 여전히 idempotency 설계가 필요하다.
Two-Phase Commit vs Eventual Consistency
2PC 와 Eventual Consistency 는 서로 대립하는 것이 아니라, 요구사항에 따라 선택하는 트레이드오프이다.
| 기준 | Two-Phase Commit | Eventual Consistency |
|---|---|---|
| 일관성 보장 시점 | 즉시 (트랜잭션 완료 시) | 지연 (수렴 시간 필요) |
| 가용성 | 낮음 (blocking) | 높음 |
| 성능 | 느림 (2 RTT + fsync) | 빠름 (로컬 쓰기) |
| 장애 영향 | 전체 트랜잭션 실패 | 일시적 불일치 허용 |
| 적합한 시나리오 | 금융 이체, 결제 | 소셜 피드, 추천, 캐시 |
실무에서는 하이브리드 접근이 일반적이다. Business Invariant 가 중요한 핵심 연산(잔액 차감, 재고 차감)에는 Strong Consistency 를 적용하고, 나머지(알림, 로그, 통계)에는 Eventual Consistency 를 적용한다.
Practical Q&A
When to Use Strong vs Eventual Consistency
- Strong Consistency: Business Invariant 가 절대 위반되어서는 안 되는 경우. 금융 트랜잭션, 재고 관리(oversell 방지), 인증/인가.
- Eventual Consistency: 일시적인 stale data 가 허용되는 경우. 소셜 미디어 피드, 검색 인덱스, 분석 대시보드, 알림 시스템, CDN 콘텐츠.
- Hybrid (가장 일반적): 핵심 경로에는 Strong Consistency, 나머지에는 Eventual Consistency.
How to Debug Consistency Issues in Production
- Correlation ID: 각 비즈니스 트랜잭션에 고유 ID 를 부여하고 모든 서비스에 전파한다.
- Distributed Tracing: Jaeger, Zipkin, OpenTelemetry 등을 활용하여 트랜잭션 흐름을 추적한다.
- Consistency Checker: 주기적으로 복제본을 비교하고 불일치를 감지하는 배치 작업을 운영한다.
- Metrics: Replication lag, conflict rate, compensating transaction rate 을 모니터링한다.
Common Pitfalls
Reading Your Own Writes
사용자가 데이터를 쓴 직후 읽었을 때 자신의 쓰기가 반영되지 않는 문제이다. 예를 들어 프로필을 수정한 뒤 새로고침했는데 이전 값이 보이는 상황이다.
해결 방법: Read-your-writes consistency 를 보장한다. 쓰기 직후 일정 시간 동안은 Primary 복제본에서 읽거나, 쓰기 시 반환된 버전보다 최신인 복제본에서만 읽는다.
Monotonic Read Inconsistency
사용자가 같은 데이터를 반복 조회할 때 시간이 역행하는 것처럼 보이는 문제이다. 첫 번째 읽기에서 최신 값을 보았다가 두 번째 읽기에서 이전 값을 보게 되는 상황이다.
해결 방법: Monotonic reads 를 보장한다. 동일한 사용자의 읽기 요청을 항상 같은 복제본으로 라우팅하거나(sticky session), 이전에 관찰한 버전 이상의 데이터만 반환하도록 한다.
Ignoring Event Ordering
모든 이벤트가 교환 가능(commutative)한 것은 아니다. "100원 출금" 후 "200원 입금"과 그 반대 순서는 잔액 검증이 있을 때 다른 결과를 낳을 수 있다.
해결 방법: 비즈니스 로직이 순서에 의존하는 경우 Causal ordering 을 사용한다. Kafka 의 partition key 를 활용하여 동일한 논리적 엔티티의 이벤트 순서를 보장할 수 있다.
Not Implementing Idempotency
"아마 일어나지 않을 것이다"는 전략이 아니다. 분산 시스템에서 재시도, rebalancing, failover 로 인해 중복 메시지는 반드시 발생한다.
원칙: 모든 이벤트 Consumer 는 멱등하게 설계해야 한다. 이것은 최적화가 아니라 필수 요구사항이다.
Stale Data in Cache
캐시와 데이터베이스 간 일관성 문제이다. 캐시에 오래된 데이터가 남아 있으면 Eventual Consistency 의 수렴 시간이 예상보다 길어진다.
해결 방법: Cache-aside 패턴에서 TTL 을 적절히 설정하거나, Write-through/Write-behind 패턴을 사용하여 캐시와 DB 의 일관성을 관리한다. Consistency window (쓰기와 수렴 사이의 최대 예상 시간)를 정의하고 모니터링하는 것이 중요하다.
Links
- CAP Theory of Design Principles for Distributed Systems
- CRDTs
- Designing robust APIs with Idempotency
- Saga
- Message Delivery in Event Driven Architecture
- eXtended Architecture
- A Deep Dive into Distributed Transactions
- Introduction message queuing
- Compensating Transaction
- When to use a CRDT-based database
- Jepsen - Consistency Models
References
- Designing Data-Intensive Applications / Martin Kleppmann / O'Reilly
- Eventually Consistent - Revisited / Werner Vogels / ACM Queue, 2008
- Principles of Eventual Consistency / Sebastian Burckhardt / NOW Publishers
- Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services / Seth Gilbert, Nancy Lynch / 2002
- Conflict-free Replicated Data Types / Marc Shapiro et al. / SSS 2011
- Consistency Tradeoffs in Modern Distributed Database System Design / Daniel Abadi / 2012
- Dynamo: Amazon's Highly Available Key-value Store / DeCandia et al. / SOSP 2007
- 도메인 주도 설계로 시작하는 마이크로서비스 개발 / 한정헌, 유해식, 최은정, 이주영 저 / 위키북스
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초2 / Alex Xu 저 / 인사이트